Join us as we return to New York on June 5 to collaborate with leaders to explore comprehensive methods for auditing AI models for bias, performance, and ethical compliance in diverse organizations. Find out how you can attend here.
As competition in the generative AI space shifts toward multimodal models, Meta has released a preview of what could be its answer to models released by frontier labs. Chameleon, its new family of models, was designed to be natively multimodal instead of assembling components with different modalities.
Although Meta has not yet released the models, their reported experiments show that Chameleon achieves peak performance in various tasks, including image captioning and visual question answering (VQA), while remaining competitive in tasks containing only text.
Chameleon’s architecture can unlock new AI applications that require a deep understanding of visual and textual information.
Multimodal models of early fusion
The most common way to create multimodal base models is to assemble models that have been trained for different modalities. This approach is called “late fusion,” in which the AI system receives different modalities, encodes them with distinct models, and then merges the encodings for inference. Although late fusion works well, it limits the models’ ability to integrate information across modes and generate sequences of interleaved images and text.
VB event
The AI Impact Tour: The AI Audit
Request an invitation
Chameleon uses a “mixed early fusion token-based” architecture, meaning it was designed from the ground up to learn from an interleaved mix of images, text, code, and other modalities . Chameleon transforms images into discrete tokens, much like language models do with words. It also uses a unified vocabulary consisting of text, code, and image tokens. This allows the same transformer architecture to be applied to sequences containing both image and text tokens.
According to the researchers, the most similar model to Chameleon is Google Gemini, which also uses an early merge token-based approach. However, Gemini uses separate image decoders in the generation phase, while Chameleon is an end-to-end model that processes and generates tokens.
“Chameleon’s unified token space allows it to reason and generate interleaved sequences of images and text seamlessly, without the need for modality-specific components,” the researchers write.
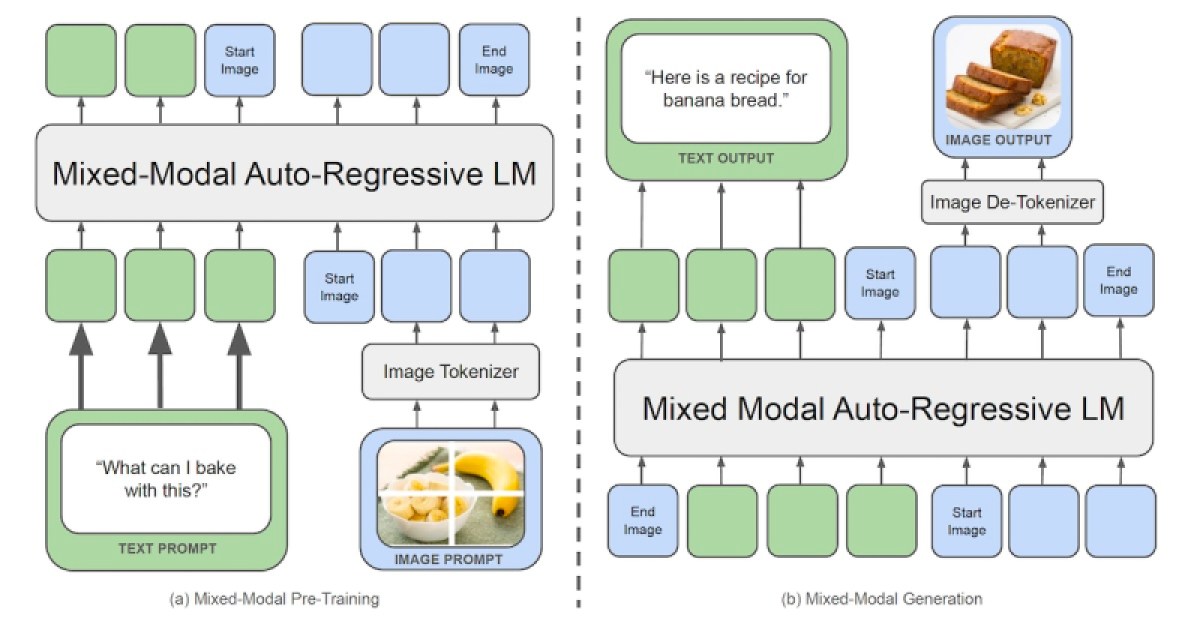
Although early fusion is very attractive, it presents significant challenges when training and scaling the model. To overcome these challenges, the researchers resorted to a series of architectural modifications and training techniques. In their article, they share details of the different experiments and their effects on the model.
Training Chameleon takes place in two stages, with a dataset containing 4.4 trillion text tokens, image-text pairs, and interleaved text and image sequences. The researchers trained a version of Chameleon with 7 and 34 billion parameters on over 5 million hours of 80GB Nvidia A100 GPU.
Chameleon in action
According to the experiments reported in the article, Chameleon can perform a diverse set of textual and multimodal tasks. In visual question answering (VQA) and image captioning, Chameleon-34B achieves peak performance, outperforming models like Flamingo, IDEFICS and Llava-1.5.
According to the researchers, Chameleon matches the performance of other models with “significantly fewer in-context training examples and with smaller model sizes, both in evaluations of pre-trained and fine-tuned models.”
One of the drawbacks of multimodality is a performance penalty in single-modal queries. For example, visual language models tend to perform worse on text-only prompts. But Chameleon remains competitive on text benchmark tests, matching models like Mixtral 8x7B and Gemini-Pro on common sense reasoning and reading comprehension tasks.
Interestingly, Chameleon can unlock new mixed reasoning and generation abilities, especially when prompts expect mixed answers with intertwined text and images. Experiments with human-evaluated responses show that overall, users preferred multimodal documents generated by Chameleon.
Last week, OpenAI and Google unveiled new models delivering rich multimodal experiences. However, they haven’t released many details about the models. If Meta continues to follow its playbook and release weights for Chameleon, it could become an open alternative to private models.
Early mergers may also inspire new research directions on more advanced models, especially as more modalities are added to the mix. For example, robotics startups are already experimenting with integrating language models into robotic control systems. It will be interesting to see how early fusion can also improve basic models of robotics.
“Chameleon represents an important step toward realizing the vision of unified foundation models capable of reasoning and flexibly generating multimodal content,” the researchers write.